

As we build Tanuki on top of the amazing MLX local inference framework we are finding some surprising new capabilities that are going to completely reframe what can and cannot be done on your own machine.
Inference without a token budget is here today!
Tanuki is a suite of tools for business and technical users that we will write more about. But for our first post I wanted to introduce a much smaller project MLXPromptCache, that we are making open source today.
As we started work on the second tool in Tanuki's suite, a cyber security workbench, we discovered a shortcoming in the MLX ecosystem; there is no local caching capability for cross prompt cases, where you want to share a common prefix with some changes, and not completely reloading the entire KVCache.
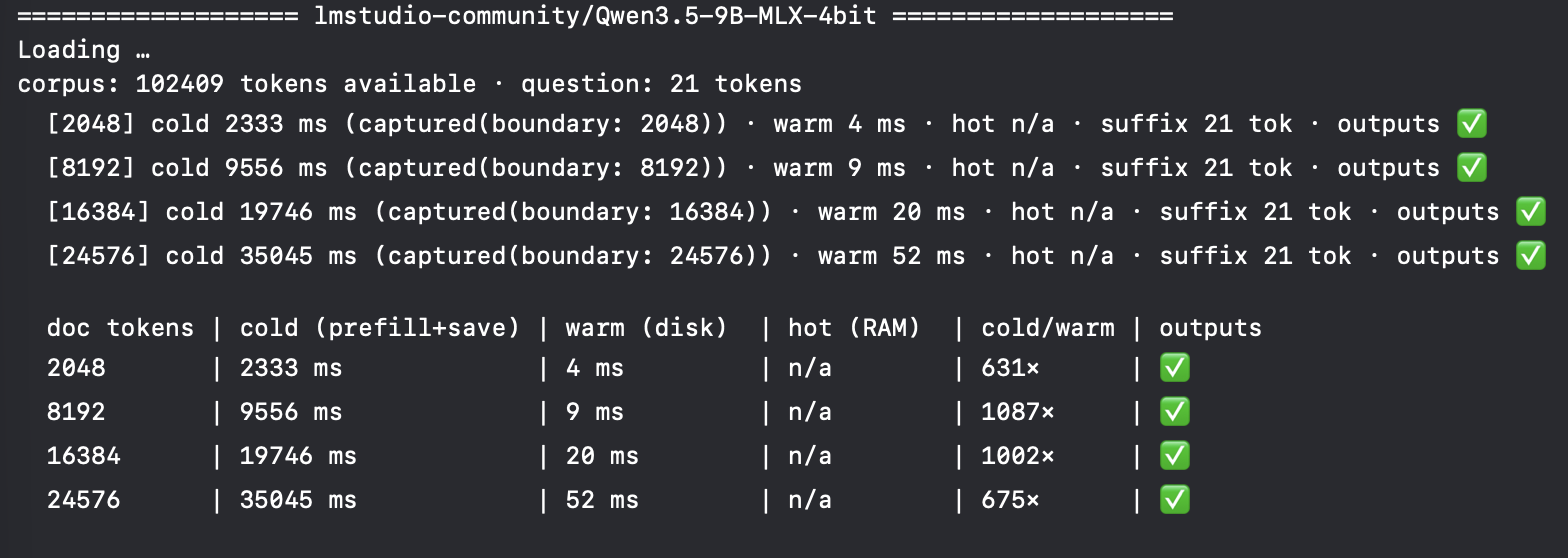
Anyone who has worked with local inference will tell you pre-fill is one of the costliest processes in machine learning. It is where the input (prompt) is converted into a matrix (if you will) of the tokens and the models underlying probabilities, to build the KVCache. This will turn a 10Kb text document into about 70Mb of pre-fill. Usually that is immediately processed by the model, which produces the output and throws everything else away.
In the cyber bench variation of Tanuki this wont do, TanukiApp is designed for using a consistent workflow across new content, and most of that content is human language, which is less token rich than say a log file is. This means that per KB, log files take MUCH longer to pre-fill than say 20 minutes of recorded speech.
Further though, in the cyber bench we will likely want to ask DIFFERENT questions of the same set of documents over and over again, this is quite literally the opposite of the original architecture of Tanuki, so we had to go digging for ways to only do the pre-fill one time and reuse it.
Sadly there is today no means to do that with Swift MLX, but we did find oMLX, an open-source tool for running agentic engineering flows locally, had PRECISELY the mechanism we require, but in Python.
No shade to Python but it doesn't hold a candle to Swift MLX, and with the effort Apple is pouring in, we can only assume the performance gap to widen.
So we ported in the capability from oMLX and found some pretty incredible numbers, 400-1100x reduction in time and effort when prefiling warm (from disk) from cache. We liked it so much we decided to open source the repo.
So if you are working with Swift MLX and would like to reduce the Time To First Token on repetitive inference tasks, you should try out MLXPromptCache.